Large-Scale Mixed-Bandwidth Deep Neural Network Acoustic Modeling for Automatic Speech Recognition
Khoi-Nguyen C. Mac, Xiaodong Cui, Wei Zhang, Michael Picheny
Khoi-Nguyen C. Mac, Xiaodong Cui, Wei Zhang, Michael Picheny
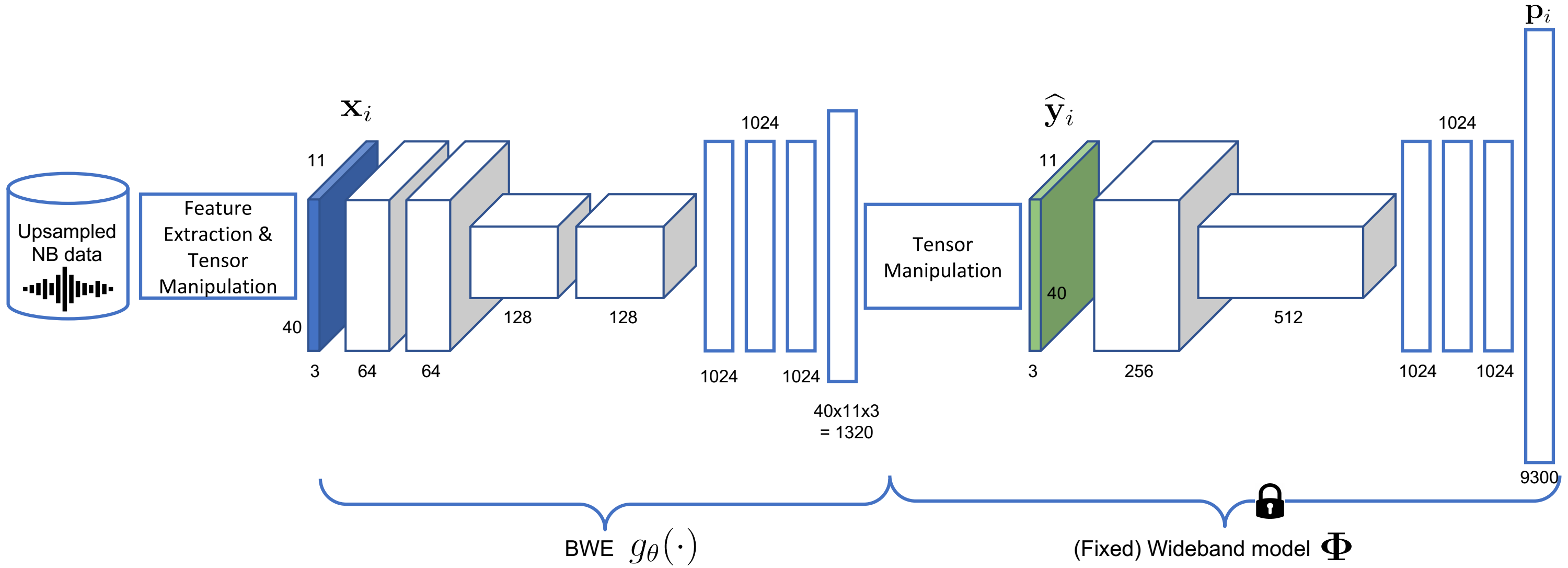
In automatic speech recognition (ASR), wideband (WB) and narrowband (NB) speech signals with different sampling rates typically use separate acoustic models. Therefore mixed-bandwidth (MB) acoustic modeling has important practical values for ASR system deployment. In this paper, we extensively investigate large-scale MB deep neural network acoustic modeling for ASR using 1,150 hours of WB data and 2,300 hours of NB data. We study various MB strategies including downsampling, up-sampling and bandwidth extension for MB acoustic modeling and evaluate their performance on 8 diverse WB and NB test sets from various application domains. To deal with the large amounts of training data, distributed training is carried out on multiple GPUs using synchronous data parallelism.

|

|
| [ISCA] [arXiv] | Slides |
@inproceedings{Mac_2019_MixBW,
author = {Khoi{-}Nguyen C. Mac and
Xiaodong Cui and
Wei Zhang and
Michael Picheny},
title = {Large-Scale Mixed-Bandwidth Deep Neural Network Acoustic Modeling for Automatic Speech Recognition},
booktitle = {Interspeech 2019, 20th Annual Conference of the International Speech Communication Association},
publisher = {{ISCA}},
month = {Sep},
year = {2019}
}